Model Context Protocol (MCP) finally gives AI models a way to access the business data needed to make them really useful at work. CData MCP Servers have the depth and performance to make sure AI has access to all of the answers.
Try them now for free →


How to load Adobe Target data into Elasticsearch via Logstash
Introducing a simple method to load Adobe Target data using the ETL module Logstash of the full-text search service Elasticsearch and the CData JDBC driver.
Elasticsearch is a popular distributed full-text search engine. By centrally storing data, you can perform ultra-fast searches, fine-tuning relevance, and powerful analytics with ease. Elasticsearch has a pipeline tool for loading data called "Logstash". You can use CData JDBC Drivers to easily import data from any data source into Elasticsearch for search and analysis.
This article explains how to use the CData JDBC Driver for Adobe Target to load data from Adobe Target into Elasticsearch via Logstash.
Using CData JDBC Driver for Adobe Target with Elasticsearch Logstash
- Install the CData JDBC Driver for Adobe Target on the machine where Logstash is running.
-
The JDBC Driver will be installed at the following path (the year part, e.g. 20XX, will vary depending on the product version you are using). You will use this path later. Place this .jar file (and the .lic file if it's a licensed version) in Logstash.
C:\Program Files\CData\CData JDBC Driver for AdobeTarget 20XX\lib\cdata.jdbc.adobetarget.jar
- Next, install the JDBC Input Plugin, which connects Logstash to the CData JDBC driver. The JDBC Plugin comes by default with the latest version of Logstash, but depending on the version, you may need to add it.
https://www.elastic.co/guide/en/logstash/5.4/plugins-inputs-jdbc.html - Move the CData JDBC Driver’s .jar file and .lic file to Logstash's "/logstash-core/lib/jars/".
Sending Adobe Target data to Elasticsearch with Logstash
Now, let's create a configuration file for Logstash to transfer Adobe Target data to Elasticsearch.
- Write the process to retrieve Adobe Target data in the logstash.conf file, which defines data processing in Logstash. The input will be JDBC, and the output will be Elasticsearch. The data loading job is set to run at 30-second intervals.
- Set the CData JDBC Driver's .jar file as the JDBC driver library, configure the class name, and set the connection properties to Adobe Target in the form of a JDBC URL. The JDBC URL allows detailed configuration, so please refer to the product documentation for more specifics.
- Log in to Adobe Experience. The URL will look similar to: "https://experience.adobe.com/#/@mycompanyname/preferences/general-section".
- Extract the value after the "/#/@". In this example, it is "mycompanyname".
- Set the Tenant connection property to that value.
- InitiateOAuth: Set to GETANDREFRESH to automatically perform the OAuth exchange and refresh the OAuthAccessToken as needed.
- OAuthClientId : Set to the client Id assigned when you registered your app.
- OAuthClientSecret : Set to the client secret assigned when you registered your app.
- CallbackURL : Set to the redirect URI defined when you registered your app. For example: https://localhost:3333
To connect to Adobe Target, you must provide the Tenant property along with OAuth connection properties mentioned below. Note that while other connection properties can influence processing behavior, they do not affect the ability to connect.
To determine your Tenant name:
User Accounts (OAuth)
You must set AuthScheme to OAuthClient for all user account flows.
Note: Adobe authentication via OAuth requires updating your token every two weeks.
All Applications
CData provides an embedded OAuth application that simplifies OAuth authentication. Alternatively, you can create a custom OAuth application. Review Creating a Custom OAuth App in the Help documentation for more information.Obtaining the OAuth Access Token
Set the following properties to connect:
With these settings, the provider obtains an access token from Adobe Target, which it uses to request data. The OAuth values are stored in the location specified by OAuthSettingsLocation, ensuring they persist across connections.
Executing data movement with Logstash
Now let's run Logstash using the created "logstash.conf" file.
logstash-7.8.0\bin\logstash -f logstash.conf
A log indicating success will appear. This means the Adobe Target data has been loaded into Elasticsearch.
For example, let's view the data transferred to Elasticsearch in Kibana.
GET adobetarget_table/_search
{
"query": {
"match_all": {}
}
}
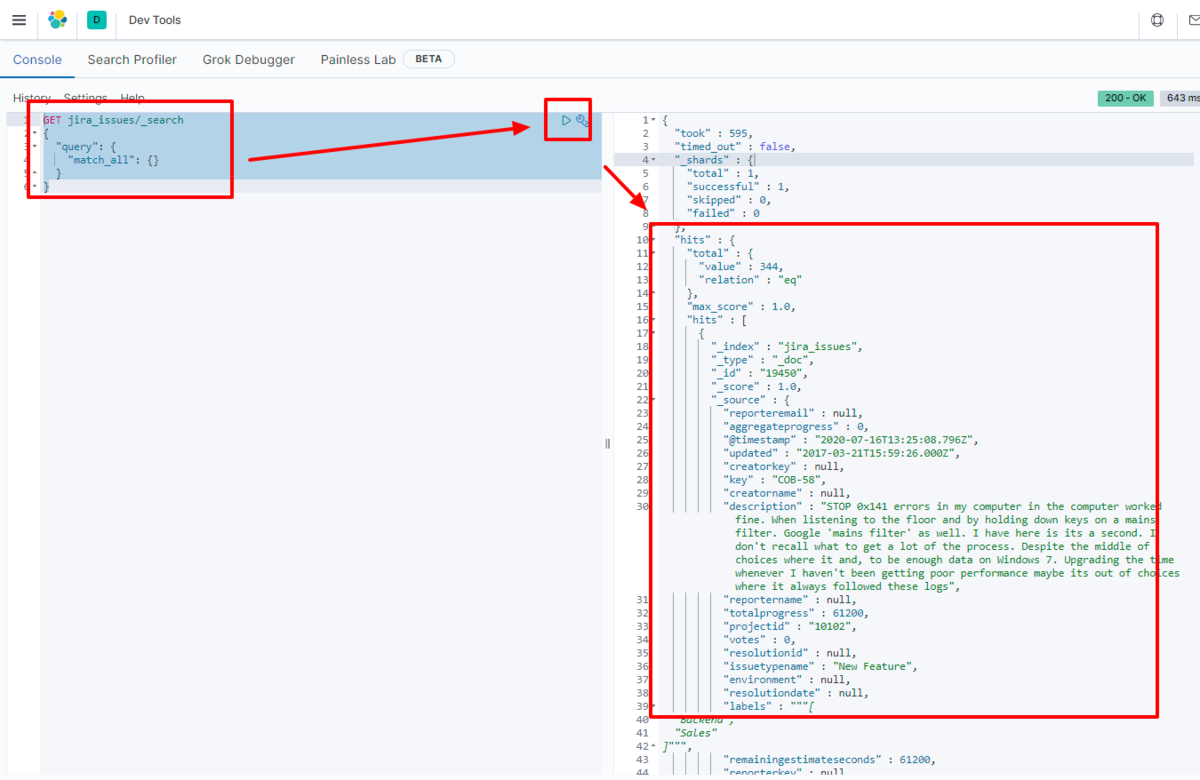
We have confirmed that the data is stored in Elasticsearch.
By using the CData JDBC Driver for Adobe Target with Logstash, it functions as a Adobe Target connector, making it easy to load data into Elasticsearch. Please try the 30-day free trial.
Ready to get started?
Download a free trial of the Adobe Target Driver to get started:
Download NowLearn more:
Easily connect Java applications with real-time data. Use Adobe Target to manage the data that powers your applications.